複数の AWS RDS クラスタを一つに統合して、インフラ費用と保守コストを削減した。
概要
私が開発に携わっている SaaS はデータストアとして Aurora MySQL の RDS クラスタを利用している。
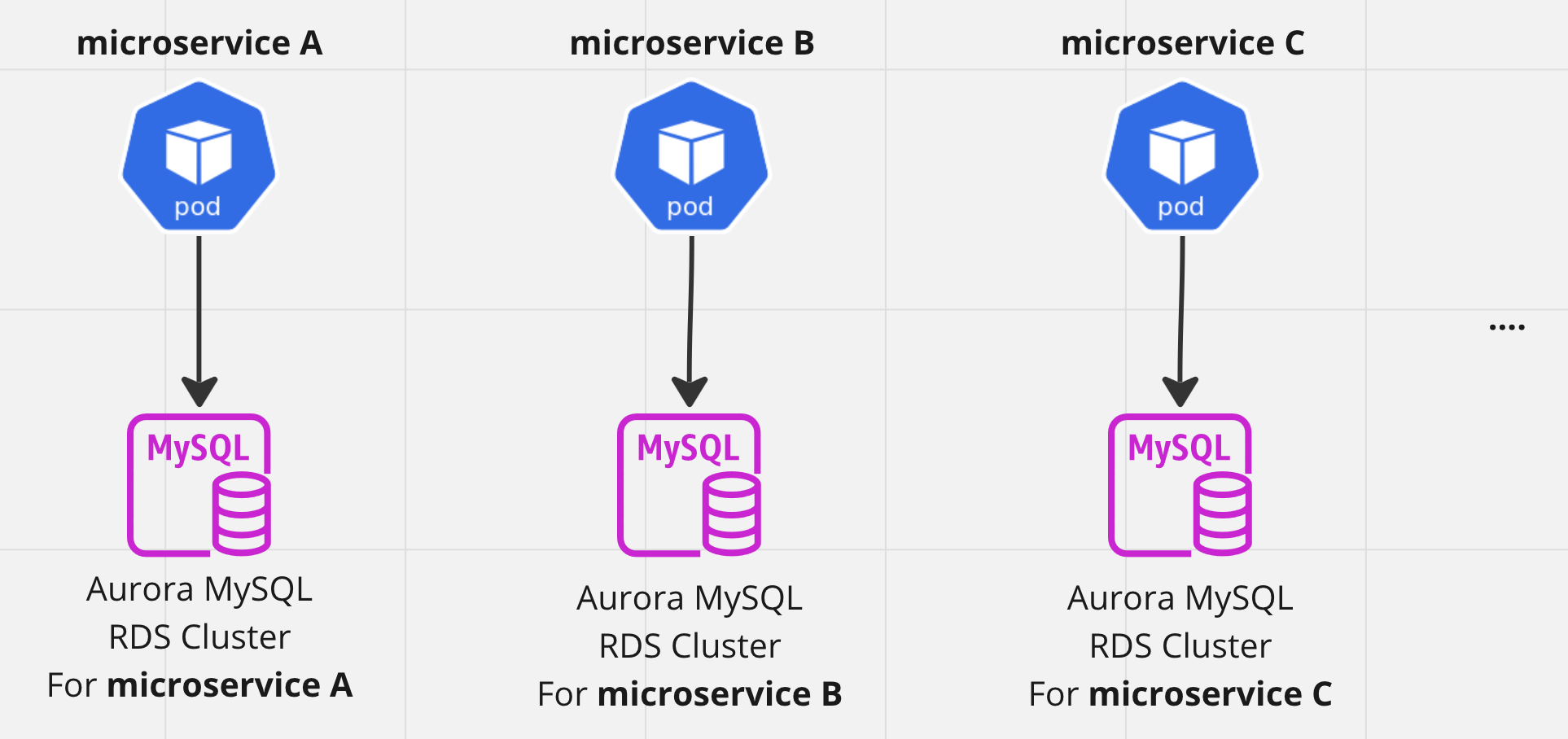
障害耐性を高めるために、マイクロサービス毎に RDS クラスタが分割されていた。
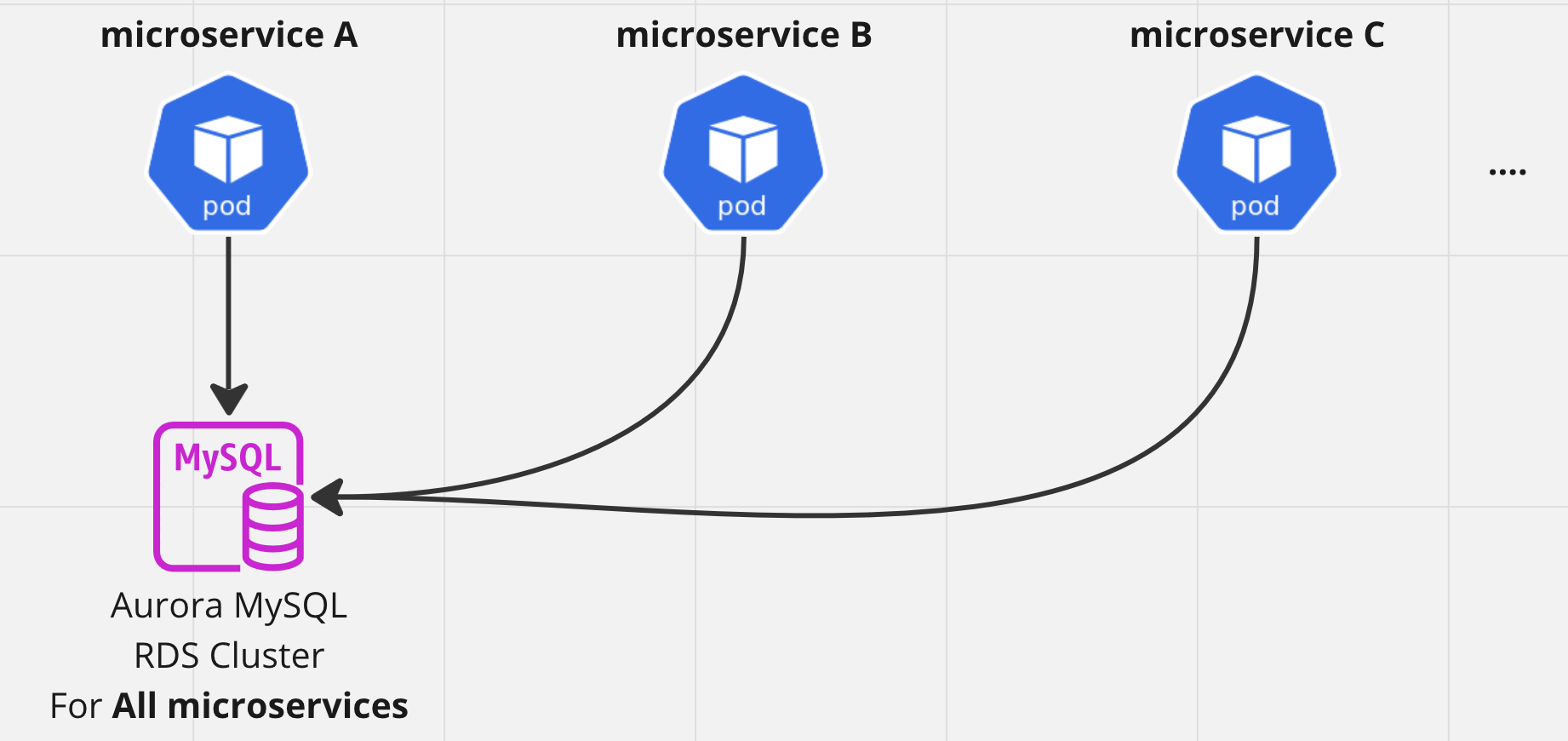
しかしインフラ費用が高額だったり、保守工数をとられていたため、統合することになった。
統合前
統合後
タスクの洗い出し
まずは統合に必要なタスクを洗い出した。
以下のようなタスクがあるだろうということになった。
検証と手順の確立
ノーメンテでの統合方法の検討
- 稼働中の RDS クラスタ間の バイナリログ(binlog)レプリケーションができるかの検証
- AWS RDS Proxy を使ったダウンタイムの軽減ができるかの検証
影響範囲の洗い出し
- アプリケーションサーバ
- Terraform, GitHub Actions, AWS Lambda
- 監視
手順の確立
- 手順書作成
- 開発環境での試験的な実施
試験
- 負荷試験
- アプリケーションサーバの動作確認
実施
- 実施スケジュールの作成と、SaaS 利用ユーザへの告知
- 実施
- 事後作業
- 振り返り
- 各種ドキュメントへの反映
ノーメンテでの統合方法の検討
要件として、ある程度ダウンタイムを減らす必要があった。
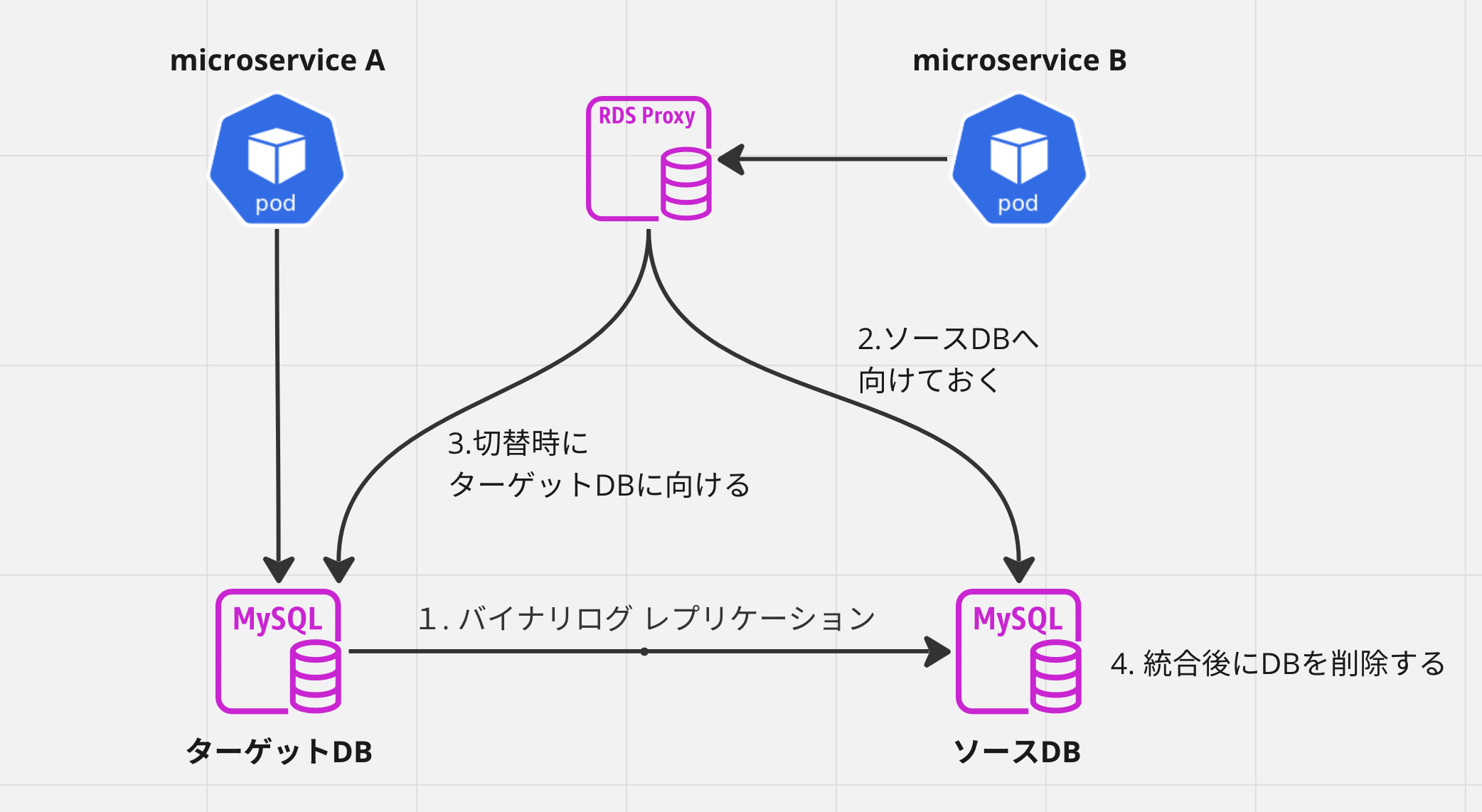
このため、統合予定の稼働中の RDS クラスタ間で バイナリログ レプリケーションをしておいて、統合時に新しいクラスタに切り替える方法を検討した。
また、アプリケーションサーバと RDS クラスタ間に AWS RDS Proxy を挟んでおくことで、アプリケーションサーバからの向き先は変更ることなく統合する方法をとった。
検証した結果、2,3分のダウンタイムで切り替えることが出来ることがわかった。
※ 切替時に手作業があったため2,3分になっているが、作業を自動化することでさらにダウンタイムを短縮できそうではあった。今回は2,3分のダウンタイムを許容できたので、そこまでの自動化は行わなかった。
切り替えイメージはこちら
なお、この記事では次のように呼ぶことにする
- 統合して無くなる方を
ソースDB(レプリケーションのマスターになる) - 統合して残る方を
ターゲットDB(レプリケーションのスレーブになる)
影響範囲の洗い出し
RDS クラスターが統合されることによる影響範囲を洗い出した。 以下が影響した。
GitHub Actions, AWS Lambda など
接続先を統合後のクラスターに変更する必要がある
データ集計プログラム
接続先を統合後のクラスターに変更する必要がある
監視
統合後のクラスターのみ監視するように変更する必要がある
手順の確立
手順は以下のようになった。
準備
ソース DB と ターゲット DB 間で、バイナリログ設定を有効化
ターゲット DB にアプリケーションサーバが使う MySQL ユーザを作成
RDS Proxy を作成
向き先は ソース DB
ソース DB のクローンを作成
※ クローンして作成された RDSクラスタ のイベントログにバイナリログのポジションが表示されるのでメモしておく
クローンしてできた DB からデータをダンプする
ターゲット DB にデータをインポート
ソース DB をマスター、ターゲット DB をスレーブとして、バイナリログレプリケーションを設定
※ このときに前の手順でメモしておいたバイナリログのポジションを使う
問題なくレプリケーションができていることを確認
アプリケーションサーバの接続先を RDS Proxy に変更
INFO
なお、通常のバイナリログ レプリケーションでは、ターゲット DB の書き込みは禁止しておくほうが安全であるが、今回はターゲット DB も利用されているため、書き込みを禁止しなかった。
MySQL スキーマ(データベース)毎に、MySQL ユーザを分けておいて、MySQL ユーザの権限を落とすことで、書き込みを禁止する方法もあった。
統合作業
ソース DB の書き込み停止
パラメータグループで
read_onlyを1に変更ソース DB でread_only が ONになっていることを以下のコマンドで確認
sqlmysql> show global variables like 'read_only'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | read_only | ON | +---------------+-------+レプリケーションが完了していることを確認
以下のようにして、レプリケーションのポジションが一致していることを確認する
ソース DB のレプリケーションのポジションを確認
sqlmysql> show master status; +----------------------------+-----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +----------------------------+-----------+--------------+------------------+-------------------+ | mysql-bin-changelog.000001 | 123456789 | | | | +----------------------------+-----------+--------------+------------------+-------------------+ターゲット DB のレプリケーションのポジションを確認
sqlmysql> show slave status\G ... Master_Log_File: mysql-bin-changelog.000001 Read_Master_Log_Pos: 109156484 ...
ターゲット DB でレプリケーションを停止
sqlmysql> stop slave;レプリケーション設定を削除
sqlmysql> call mysql.rds_reset_external_master;RDS Proxy の向き先をターゲット DB に変更
これで、ターゲット DB に向けてアプリケーションが動き始める
事後作業
- ソース DB の削除
- アプリケーションサーバの接続先を RDS Proxy から ターゲットDBに向ける
- RDS Proxy の削除
- その他、洗い出しておいて影響範囲の修正
上記の作業を、全ての RDS クラスタに対して行う。
INFO
Aurora MySQL v2 (MySQL 5.7 互換) では、マルチソースレプリケーションがサポートされていないため、一度に複数の RDS クラスタを統合することはできなかった。
試験
負荷試験
統合後のクラスターに向けて負荷試験を実施し、パフォーマンスが要件を満たすことを確認した。
アプリケーションサーバの動作確認
統合後のクラスターに向けてアプリケーションの e2e テストを実施して、アプリケーションが正常に動作することを確認した。
実施
統合作業のスケジュールを作成し、SaaS 利用ユーザへのメンテナンスの告知を行った。
切り替えは深夜帯に行った。
振り返り
本番・開発環境を含めて 50 クラスタあったものを大幅に減らすことができ、インフラ費用と保守コストを大きく削減できた
だいたい 8ヶ月くらいはかかった
- 2023年1,2月 : 統合手順の調査・検証
- 2024年3月 : 事前準備(MySQL ユーザの整理など)
- 2024年4月 : (4月は別プロジェクトで忙しくて何もできなかった)
- 2024年5,6月 : パフォーマンス検証、動作検証
- 2024年7月 : テスト環境の統合実施
- 2024年8,9月 : 本番環境の統合実施
※ 統合プロジェクト以外にも色々やっていたので、統合プロジェクトにかけた時間は実際にはもう少し短い。